Capítulo 7 ¿Qué es una red neuronal?
Las redes neuronales artificiales están inspiradas en la forma en la que las neuronas de nuestro cerebro trabajan en conjunto para resolver una tarea compleja. Éstas modelan una variable respuesta, ya sea de tipo continua o categórica, como función de las covariables a través de la composición de funciones no lineales.
De manera general, una red neuronal consiste de una arquitectura, una regla de activación y una regla de salida.
Arquitectura: Puede ser descrita vía un gráfo dirigido cuyo nodos son llamados neuronas. Existen una grán cantidad de arquitecturas dependiendo de la naturaleza del grafo i.e. de las relaciones entre los nodos.
Una descripción bastante completa de las distintas arquitecturas y sus nombres puede ser consultada en este sitio.
Regla de activación: Típicamente el valor en cada nodo \(v\) puede ser calculado como \[x_v = f(\sum_{u \rightarrow v}\beta_{uv}x_u)\] donde la suma se obtiene sobre los nodos predecesores de \(v\) y \(\beta_{uv}\) son los coeficientes (desconocidos) de la red.
A la función \(f(\cdot)\) se le conoce como función de activación. Las más comúnmente usadas son la sigmoide logística \(f(x) = \frac{e^y}{1+e^y}\) y la función rectificadora \(f(x) = \max\{{y,0}\}\)
7.0.1 Ejemplo
Dada la siguiente arquitectura calcularemos el valor de salida dado por el nodo \(x_6\).
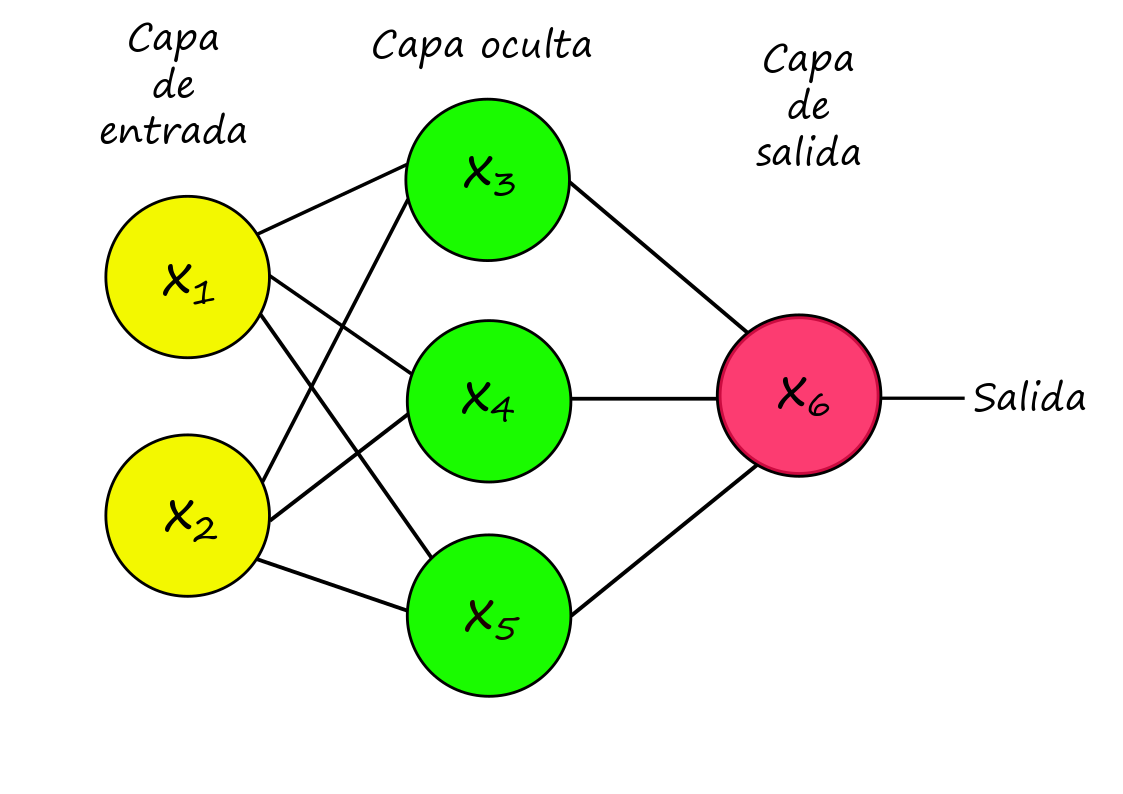
\[\begin{align*} x_{6} & =f\left(\beta_{3,6}\cdot x_{3}+\beta_{4,6}\cdot x_{4}+\beta_{5,6}\cdot x_{5}\right)\\ & \hookrightarrow x_{3}=f\left(\beta_{1,3}\cdot x_{1}+\beta_{2,3}\cdot x_{2}\right)\\ & \hookrightarrow x_{4}=f\left(\beta_{1,4}\cdot x_{1}+\beta_{2,4}\cdot x_{2}\right)\\ & \hookrightarrow x_{5}=f\left(\beta_{1,5}\cdot x_{1}+\beta_{2,5}\cdot x_{2}\right)\\ & \vdots \end{align*}\]
donde \(f(\cdot)\) es la función de activación.
N.B. Si suponemos que \(f(x) = \mathbb{I}(x)\) y que la red consiste de una sola capa entonces el problema a resolver será el de regresión lineal.
Nodos de sesgo: Dependiendo de la utilidad, podríamos estar interesados, como en el problema de regresión lineal, en un término de intercepto o nivel _base-, para ello puede simplemente crearse un nodo extra cuyo valor sea la constante 1.
Regla de salida: En el nodo de salida \(v\), se calcula: \[s_v = \sum_{u\rightarrow v}\beta_{uv}x_u\] y en lugar de aplicar la función de activación \(f(\cdot)\), se usa una regla de salida para obtener el valor o vector de ajuste/predicción.
Por ejemplo, en un problema de clasificación de \(N\) clases, la capa de salida consitirá de \(N\) nodos, cada uno asociado a cada clase; la predicción/ajuste \(\hat{y}\in \mathbb{R}^p\) está dada por \[\hat{y}=\arg max\{s_{vn}\}\]
Notemos que para este ejemplo, si la arquitectura de la red carece de capas intermedias/ocultas y con función de activación sigmoide logística entonces el modelo corresponde al de regresión logística múltiple.
Al igual que en los modelos logísticos, podemos hacer que la red neuronal tenga como salida un vector de probabilidades \(z=(z_1,\dots,z_N)\) dado por \[z_n=\frac{e^{s_{v_n}}}{e^{s_{v_1}}+\dots+e^{s_{v_N}}}\]
Al proceso de normalización de los valores exponenciados se le conoce como la operación softmax.
De manera particular una red neuronal cuya arquitectura está representada por un grafo dirigido no cíclico, (feedforward) con función de activación sigmoide logística y regla de salida softmax es un modelo paramétrico descrito por:
\[y \sim Multinomial(1, (p_1,\dots,p_N)\] \[(p_1,\dots,p_N)=g^{nnet}(x_v; \{\beta_{uv}:u\rightarrow v\})\]
7.1 Teorema de Universalidad
La flexibilidad y el poder de las redes neuronales radica en la estructura de composición de funciones de activación no lineales. El siguiente teorema implica que una red neuronal puede aproximar cualquier función; en particular, es relevante el poder aproximar cualquier modelo no paramétrico de regresión.
Teorema. Sea \(\Delta^{L}=\left\{ \left(y_{1},\ldots,y_{L}\right)\in\mathbb{R}_{\geq0}^{L}\,|\,y_{1}+\dots+y_{L}=1\right\} \in \mathbb{R}^{L}\), y \(B\subseteq\mathbb{R}^{p}\) un conjunto acotado que contiene al origen y \(\mu\) una medida de probabilidad en \(B\).
Para \(g:\,B\rightarrow\Delta\) una función medible arbitraria existe una red neuronal totalmente conectada (feedforward), de una capa oculta que tiene \(m\) neuronas, activación sigmoide y regla output softmax tal que su correspondiente función de probabilidades \(g^{NNET}\) satisface:
\[\int_{B}\left\lVert g-g^{NNET}\right\lVert _{2}^{2}d\mu\leq\frac{Clog^{2}\left(n\right)}{n}\]
para alguna constante universal \(C\).
7.2 Entrenamiento de una red neuronal
En el ámbito del machine learning se le conoce como entrenamiento al proceso de encontrar buenos estimadores de los parámetros del modelo usado, en este caso, de la red neuronal.
Sea \(\beta = (\beta_{uv}; u\rightarrow v)\) el vector de parámetros de una red neuronal. Dados los datos de entrenamiento \((x^1,y^1),\dots,(x^n,y^n)\), la log-verosimilitud de \(\beta\) está dada por:
\[{\it l}\left(\beta\right)=\sum_{i=1}^{n}\sum_{{\it l}=1}^{L}\mathbb{I}_{\left\{ y_{i}={\it l}\right\} }log\left(\frac{e^{s_{v_{{\it l}}}\left(x_{i},\beta\right)}}{e^{s_{v_{1}}\left(x_{1},\beta\right)}+\dots+e^{s_{v_{L}}\left(x_{L},\beta\right)}}\right) =\colon \sum_{i=1}^{n}{\it l}_{i}\left(\beta\right)\] A continuación mostraremos cómo podemos maximizar la log-verosimilitud para obtener los parámetros.
7.2.1 Back-propagation
Gracias a la estructura de composición de funciones del modelo, la derivada puede encontrarse fácilmente usando la regla de la cadena.
7.2.1.1 Ejemplo (back-propagation).
Consideremos la siguiente red neuronal:
Dado, el ejemplo de entrenamiento \(x^i=(x_1^i,x_2^i)\) con etiqueta/valor \(y^i\) la red neuronal calcula la probabilidad de salida \(z_1=\mathbb{P}[Y=1|X = x^i]\) de la siguiente forma:
\[\begin{align*} s_{3}=\beta_{1,3}x_{1}+\beta_{2,3}x_{2} & \,\,\,\,\,\,\,\,\,\,x_{3}\leftarrow f\left(s_{3}\right)\\ s_{4}=\beta_{1,4}x_{1}+\beta_{2,4}x_{2} & \,\,\,\,\,\,\,\,\,\,x_{4}\leftarrow f\left(s_{4}\right)\\ s_{5}=\beta_{1,5}x_{1}+\beta_{2,5}x_{2} & \,\,\,\,\,\,\,\,\,\,x_{5}\leftarrow f\left(s_{5}\right)\\ s_{6}=\beta_{3,6}x_{3}+\beta_{4,6}x_{4}+\beta_{5,6}x_{5} & \,\,\,\,\,\,\,\,\,\,z_{1}\leftarrow f\left(s_{6}\right) \end{align*}\]
Donde, por facilidad, estamos considerando que \(f(x)=\frac{e^x}{1+e^x}\).
El valor de la log-verosimilitud para este ejemplo de entrenamiento se calcula como:
\[{\it l}_{i}\left(\beta;\,\left(x^{i},\,y^{i}\right)\right)=\mathbb{I}_{\left\{ y^{i}=1\right\} }log\left(z_{1}\right)+\mathbb{I}_{\left\{ y^{i}=2\right\} }log\left(1-z_{1}\right)\]
Y el gradiente estocástico como:
\(\frac{\partial l}{\partial z_1} = \frac{\mathbb{I}_{\{y^1=1\}}}{z_1}-\frac{\mathbb{I}_{\{y^1=2\}}}{1-z_1}\)
\(\frac{\partial l}{\partial s_6} = \frac{\partial l}{\partial z_1}\cdot f'(s_6)\)
\(\frac{\partial l}{\partial \beta_{3,6}} = \frac{\partial l}{\partial s_6}\cdot x_3\)
\(\frac{\partial l}{\partial \beta_{4,6}} = \frac{\partial l}{\partial s_6}\cdot x_4\)
\(\frac{\partial l}{\partial \beta_{5,6}} = \frac{\partial l}{\partial s_6}\cdot x_5\)
\(\frac{\partial l}{\partial x_3} = \frac{\partial l}{\partial s_6}\cdot \beta_{3,6}\)
\(\frac{\partial l}{\partial x_4} = \frac{\partial l}{\partial s_6}\cdot \beta_{4,6}\)
\(\frac{\partial l}{\partial x_5} = \frac{\partial l}{\partial s_6}\cdot \beta_{5,6}\)
\(\frac{\partial l}{\partial s_3} = \frac{\partial l}{\partial x_3}\cdot f'(s_3)\)
\(\frac{\partial l}{\partial s_4} = \frac{\partial l}{\partial x_4}\cdot f'(s_4)\)
\(\frac{\partial l}{\partial s_4} = \frac{\partial l}{\partial x_5}\cdot f'(s_5)\)
\(\frac{\partial l}{\partial \beta_{1,3}} = \frac{\partial l}{\partial s_3}\cdot x_1\)
\(\frac{\partial l}{\partial \beta_{2,3}} = \frac{\partial l}{\partial s_3}\cdot x_2\)
\(\frac{\partial l}{\partial \beta_{1,4}} = \frac{\partial l}{\partial s_4}\cdot x_1\)
\(\frac{\partial l}{\partial \beta_{2,4}} = \frac{\partial l}{\partial s_4}\cdot x_2\)
\(\frac{\partial l}{\partial \beta_{1,5}} = \frac{\partial l}{\partial s_5}\cdot x_1\)
\(\frac{\partial l}{\partial \beta_{2,5}} = \frac{\partial l}{\partial s_5}\cdot x_2\)
\(\frac{\partial l}{\partial x_1} = \frac{\partial l}{\partial s_3}\cdot \beta_{1,3}+\frac{\partial l}{\partial s_4}\cdot \beta_{1,4}+\frac{\partial l}{\partial s_5}\cdot \beta_{1,5}\)
\(\frac{\partial l}{\partial x_2} = \frac{\partial l}{\partial s_3}\cdot \beta_{2,3}+\frac{\partial l}{\partial s_4}\cdot \beta_{2,4}+\frac{\partial l}{\partial s_5}\cdot \beta_{2,5}\)
En resúmen, para optimizar la verosimilitud por gradiente estocástico debemos seguir lo siguientes pasos (llamados back-propagation):
1. Inicializar los parámetros \(\hat{\beta}^{(0,n)}=\{\hat{\beta_{u,v}}^{(0,n)}:u\rightarrow v\}\)
2. Para cada fase de entrenamiento \(t=1,2,\dots\)
Para \(i = 1,2,\dots,n\) - Obtener el vector de probabilidades \(z = (z_1,\dots,z_N)\) usando como input el ejemplo \(x^i\) y los parámteros \(\hat{\beta}^{(t, i-1)}\)
- Obtener las derivadas parciales del la log-verosimilitud con respecto a:
\[\{z_l:1\leq l\leq N\} \ \{s_v:v\in S_M\} \ \{\beta_{uv}:u\in S_{M-1}, v\in S_M\}\] \[\{x_v:v\in S_{M-1}\} \ \{s_v:v\in S_{M-1}\} \ \{\beta_{uv}:u\in S_{M-2}, v\in S_{M-1}\}\] \[\{x_v:v\in S_{M-2}\} \ \{s_v:v\in S_{M-2}\} \ \{\beta_{uv}:u\in S_{M-3}, v\in S_{M-1}\}\] \[\vdots\] \[\{x_v:v\in S_2\} \ \{s_v:v\in S_2\} \ \{\beta_{uv}:u\in S_1, v\in S_2\}\]
en ese orden.
3. Actualizar los parámetros \[\hat{\beta_{uv}}^{(t,i)} \leftarrow \hat{\beta_{uv}}^{(t,i-1)}+\alpha \cdot \frac{\partial l_i}{\partial \beta_{uv}}\]
En general, a este procedimiento de optimización se le conoce como descenso gradiente.
7.2.2 Saturación
Si durante el proceso de entrenamiento, algún nodo \(v\) tiene una valor \(|s_v|\) muy grande entonces el valor de \(f'(s_v)\) será muy cercano a cero para funciones de activación sigmoides.
Debido a la regla de la cadena, los valores de \(\beta_{uv}\) se moverán muy lentamente hacia el óptimo, en este caso se dice que el nodo \(v\) está saturado.
Para evitar problemas de saturación al inicio del entrenamiento comúnmente debemos estandarizar las covariables para que tengan media cero y varianza unitaria.
También es conveniente inicializar los parámetos \(\hat{\beta}^{(0,n)}\) cercanos a cero, comúnmente elegidos uniformemente entre \([-c,c]\) para \(c \in (0,1)\).
Sin embargo debemos tener cuidado pues si \(\hat{\beta}^{(0,n)}=0\) entonces \(\frac{\partial l}{\partial x_v}=0 \ \forall \ v\in S_{M-1}\) lo que hará que el algoritmo no se mueva.
7.2.3 Regularización
Un problema típico en las redes neuronales es que suelen sobre ajustar los datos de entrenamiento dado que suelen haber más parámetros que variables.
Una forma de regularizar es imponer una penalización equivalente al cuadrado de los parámetros, también llamada ridge o L2, a la log-verosimilitud y maximizar respecto a esta log-verosimilitud penalizada.
\[{\it l}\left(\beta\right)^{ridge}={\it l}\left(\beta\right)+\frac{\lambda}{2}||\beta||_2^2 = \sum_{i=1}^{n}\sum_{{\it l}=1}^{L}\mathbb{I}_{\left\{ y_{i}={\it l}\right\} }log\left(\frac{e^{s_{v_{{\it l}}}\left(x_{i},\beta\right)}}{e^{s_{v_{1}}\left(x_{1},\beta\right)}+\dots+e^{s_{v_{L}}\left(x_{L},\beta\right)}}\right)+\frac{\lambda}{2}||\beta||_2^2\]
7.3 Redes Neuronales en R
Función para calcular tamaño de la capa
get_layer_size <- function(x, y, hidden_neurons) {
n_x <- dim(x)[1]
n_h <- hidden_neurons
n_y <- dim(y)[1]
size <- list("n_x" = n_x,
"n_h" = n_h,
"n_y" = n_y)
return(size)
}Función para inicializar los parámetros aleatoriamente
random_params <- function(x, layer_size){
m <- dim(data.matrix(x))[2]
n_x <- layer_size$n_x
n_h <- layer_size$n_h
n_y <- layer_size$n_y
w1 <- matrix(runif(n_h * n_x), nrow = n_h, ncol = n_x, byrow = TRUE) * 0.01
b1 <- matrix(rep(0, n_h), nrow = n_h)
w2 <- matrix(runif(n_y * n_h), nrow = n_y, ncol = n_h, byrow = TRUE) * 0.01
b2 <- matrix(rep(0, n_y), nrow = n_y)
params <- list("w1" = w1,
"b1" = b1,
"w2" = w2,
"b2" = b2)
return(params)
}Función de activación sigmoide
Función de propagación forward
forward_prop <- function(x, params, layer_size){
m <- dim(x)[2]
n_h <- layer_size$n_h
n_y <- layer_size$n_y
w1 <- params$w1
b1 <- params$b1
w2 <- params$w2
b2 <- params$b2
b1_new <- matrix(rep(b1, m), nrow = n_h)
b2_new <- matrix(rep(b2, m), nrow = n_y)
z1 <- w1 %*% x + b1_new
a1 <- sigmoid_activation(z1)
z2 <- w2 %*% a1 + b2_new
a2 <- sigmoid_activation(z2)
cache <- list("z1" = z1,
"a1" = a1,
"z2" = z2,
"a2" = a2)
return(cache)
}Función para obtener el costo
get_cost <- function(x, y, cache) {
m <- dim(x)[2]
a2 <- cache$a2
logprobs <- (log(a2) * y) + (log(1-a2) * (1-y))
cost <- -sum(logprobs/m)
return(cost)
}Función para aplicar backward propagation
backward_prop <- function(x, y, cache, params, layer_size){
m <- dim(x)[2]
n_x <- layer_size$n_x
n_h <- layer_size$n_h
n_y <- layer_size$n_y
a2 <- cache$a2
a1 <- cache$a1
w2 <- params$w2
dz2 <- a2 - y
dw2 <- 1/m * (dz2 %*% t(a1))
db2 <- matrix(1/m * sum(dz2), nrow = n_y)
db2_new <- matrix(rep(db2, m), nrow = n_y)
dz1 <- (t(w2) %*% dz2) * (1 - a1^2)
dw1 <- 1/m * (dz1 %*% t(x))
db1 <- matrix(1/m * sum(dz1), nrow = n_h)
db1_new <- matrix(rep(db1, m), nrow = n_h)
grads <- list("dw1" = dw1,
"db1" = db1,
"dw2" = dw2,
"db2" = db2)
return(grads)
}Función para actualizar los parámetros
update_params <- function(grads, params, learning_rate){
w1 <- params$w1
b1 <- params$b1
w2 <- params$w2
b2 <- params$b2
dw1 <- grads$dw1
db1 <- grads$db1
dw2 <- grads$dw2
db2 <- grads$db2
w1 <- w1 - learning_rate * dw1
b1 <- b1 - learning_rate * db1
w2 <- w2 - learning_rate * dw2
b2 <- b2 - learning_rate * db2
updated_params <- list("w1" = w1,
"b1" = b1,
"w2" = w2,
"b2" = b2)
return (updated_params)
}Función de entrenamiento de la red neuronal
train_nn <- function(x, y, iters, hidden_neurons, learning_rate){
layer_size <- get_layer_size(x, y, hidden_neurons)
initial_params <- random_params(x, layer_size)
cost_history <- c()
for (i in 1:iters) {
fwd_prop <- forward_prop(x, initial_params, layer_size)
cost <- get_cost(x, y, fwd_prop)
back_prop <- backward_prop(x, y, fwd_prop, initial_params, layer_size)
updated_params <- update_params(back_prop, initial_params, learning_rate = learning_rate)
initial_params <- updated_params
cost_history <- c(cost_history, cost)
if (i %% 1000 == 0) cat("Iteration", i, " | Cost: ", cost, "\n")
}
model <- list("updated_params" = updated_params,
"layer_size" = layer_size,
"cost_hist" = cost_history)
return(model)
}Función para hacer predicciones
predict_nn <- function(x, trained_model){
fwd_prop <- forward_prop(x, trained_model$updated_params, trained_model$layer_size)
pred <- fwd_prop$a2
return(pred)
}Aplicación a datos de default crediticio
library(dplyr)
library(magrittr)
library(fastDummies)
datos <- read.csv(url("https://raw.githubusercontent.com/alberto-mateos-mo/seminario-est-fciencias/master/03_linear_models/logistic/data/Default.csv"))
datos %<>%
select(-purpose, -personal_status, -property_magnitude, -other_payment_plans, -housing, -job, -num_dependents, -own_telephone, -foreign_worker)
datos <- dummy_cols(datos)
x_vars <- t(scale(datos[,c(1,3:7,9:13)]))
y_var <- t(as.matrix(datos[,8]))
model <- train_nn(x_vars, y_var, hidden_neurons = 10, iters = 10000, learning_rate = 0.9)
probas <- predict_nn(x_vars, model)
clase <- round(probas)
caret::confusionMatrix(as.factor(y_var), as.factor(clase))