Capítulo 17 K-medias
Es un algorítmo iterativo descendiente cuyo uso está limitado a conjuntos de datos numéricos.
La idea detrás del algorítmo es encontrar clústers cuya variación interna sea tan pequeña como sea posible.
La variación interna de un clúster \(C_k\) es una medida \(W(C_k)\) de qué tanto difieren las observaciones pertenecientes a un clúster, por lo que buscamos resolver el problema:
\[\begin{equation} \min_{C_1,\dots,C_k}\{\sum_{k=1}^K W(C_k)\} \tag{17.1} \end{equation}\]
Comúnmnete se utiliza la distancia euclideana como medida de disimilaridad.
No se ha probado que exista algún algorítmo que resuelva el problema (17.1), sin embargo existen heurísticas que intentan resolverlo parcialmente.
17.1 Algorítmo k-medias
Tomar una partición de tamaño \(k\) de manera aleatoria.
Para \(x\in X\), se asigna a \(C_j\), donde \[||x-\bar{x}_{C_j}|| = inf||x-\bar{x}_{C_l}||\]
Repetir el paso 2 hasta que ningún \(C_j\) cambie.
Es decir, el algoritmo k-medias es un proceso iterativo que divide un conjunto de datos en \(K\) grupos excluyentes. Este método es usado extensamente en la literatura, porque es un método sencillo de implementar que utiliza centroides (prototipos) para la representación de los clusters.
La calidad de los clusters es mediada por el criterio de variación interna.
Este algoritmo produce clusters compactos (de poca dispersión en el interior), pero no toma en consideración la distancia entre clusters, y además el uso de la norma dos hace que el algoritmo sea sensible en presencia de valores atípicos.
17.2 Variantes
En términos generales las variantes del algoritmo k-medias difieren en el momento del algoritmo en que se hace la asignación de clusters, entre las variantes más utilizadas en la práctica están las siguientes:
Algoritmo de Forgy-Lloyd: los centroides son recalculados después de que todos los individuos fueron asignados. El algoritmo realiza iteraciones hasta que se obtiene la convergencia.
Algoritmo de McQueen: Los centroides son recalculados inmediatamente después de cada asignación, y al final de todas las asignaciones. El algoritmo da un único barrido a los datos.
Algoritmo de Hartigan: Se selecciona un elemento de cada partición, después se recalculan los centroides sin considerar los elementos seleccionados. Por último se asignan los elementos seleccionados al cluster cuyo centroide sea el más cercano.
17.3 Desventajas
Sensibilidad a la partición inicial: como el algoritmo consiste de una búsqueda local, este es muy sensible a la selección inicial de clusters.
Falta de robustéz: esta desventaje se hereda del hecho de que la media y varianza son sensibles ante valores atípicos.
Número de clusters desconocido: el algoritmo no proporciona información alguna del número de clusters.
No es adecuado para variables nominales: no hay una definición de media muestral para tales variables.
17.4 K-medias en R
Usaremos los datos de personajes de marvel para tratar de identificar grupos subyacentes de ellos.
marvel <- read.csv("example_data/charcters_stats.csv")
marvel <- marvel[-419,]
nombres <- marvel$Name
marvel <- marvel %>%
dplyr::select(-Total, -Alignment, -Name)
rownames(marvel) <- nombres
grupos <- kmeans(marvel, centers = 2, algorithm = "Hartigan-Wong", nstart = 1)Variación interna
## [1] 1535899.3 176249.5## [1] 1712149Visualización de los grupos
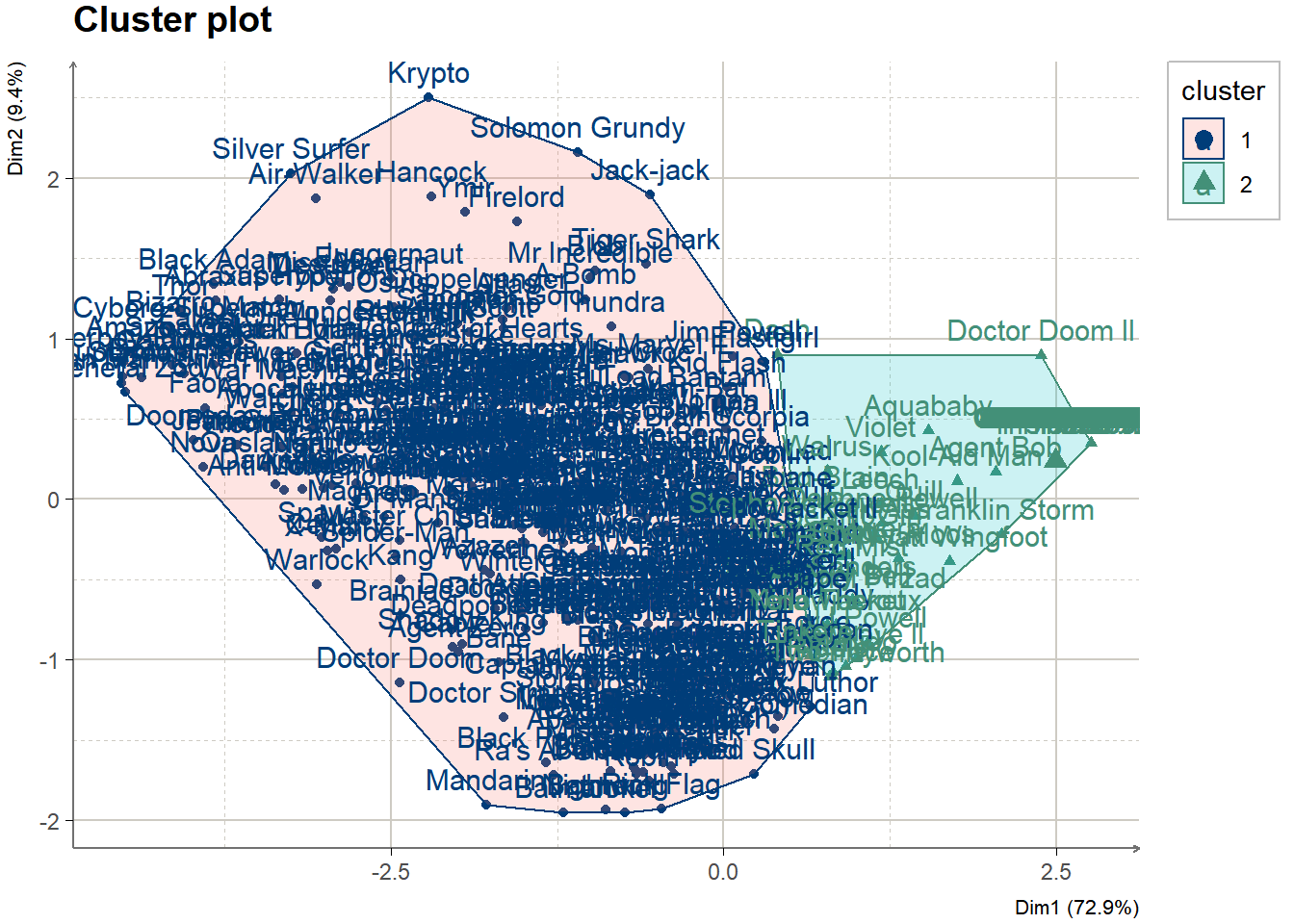
Distinta cantidad de grupos
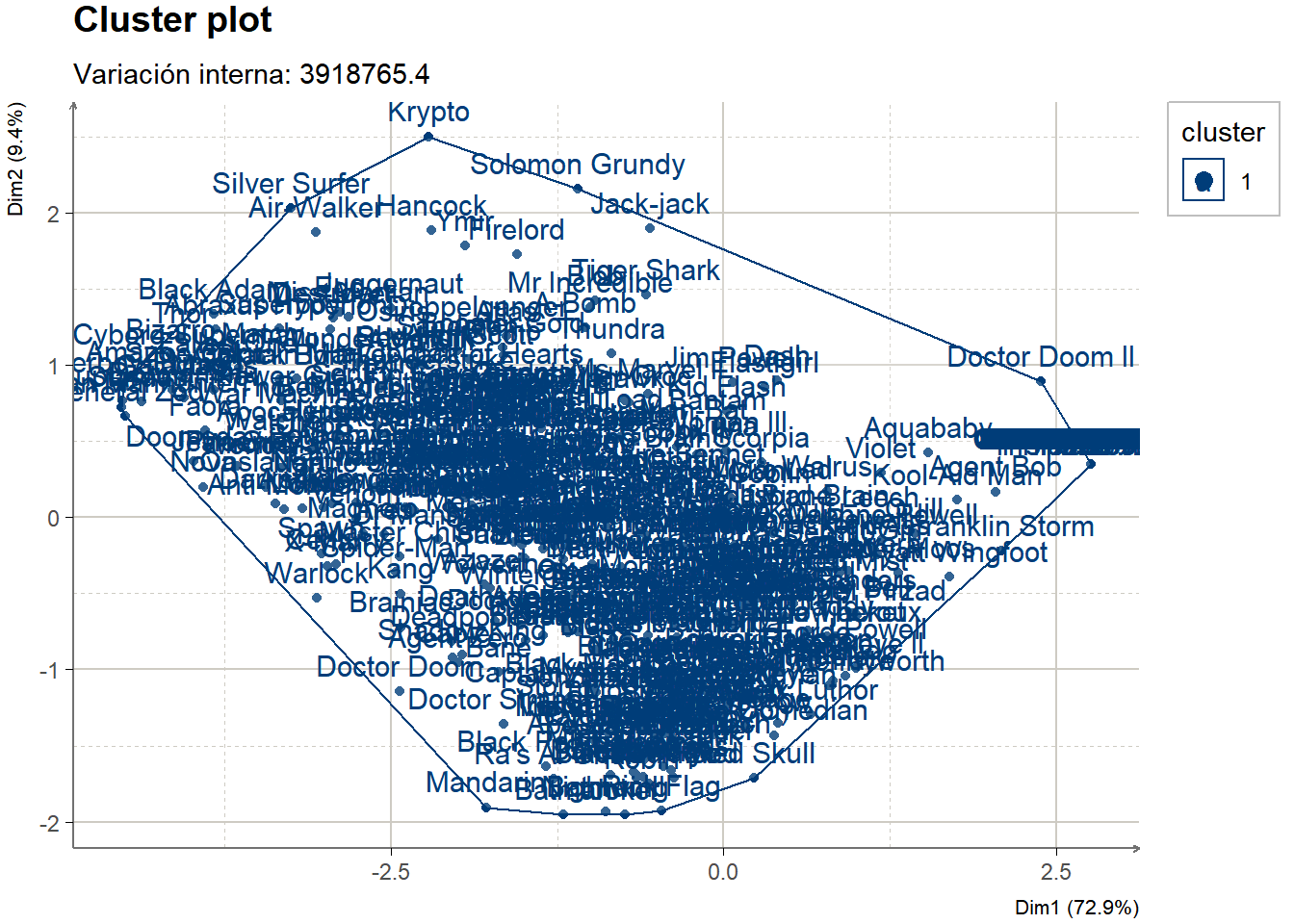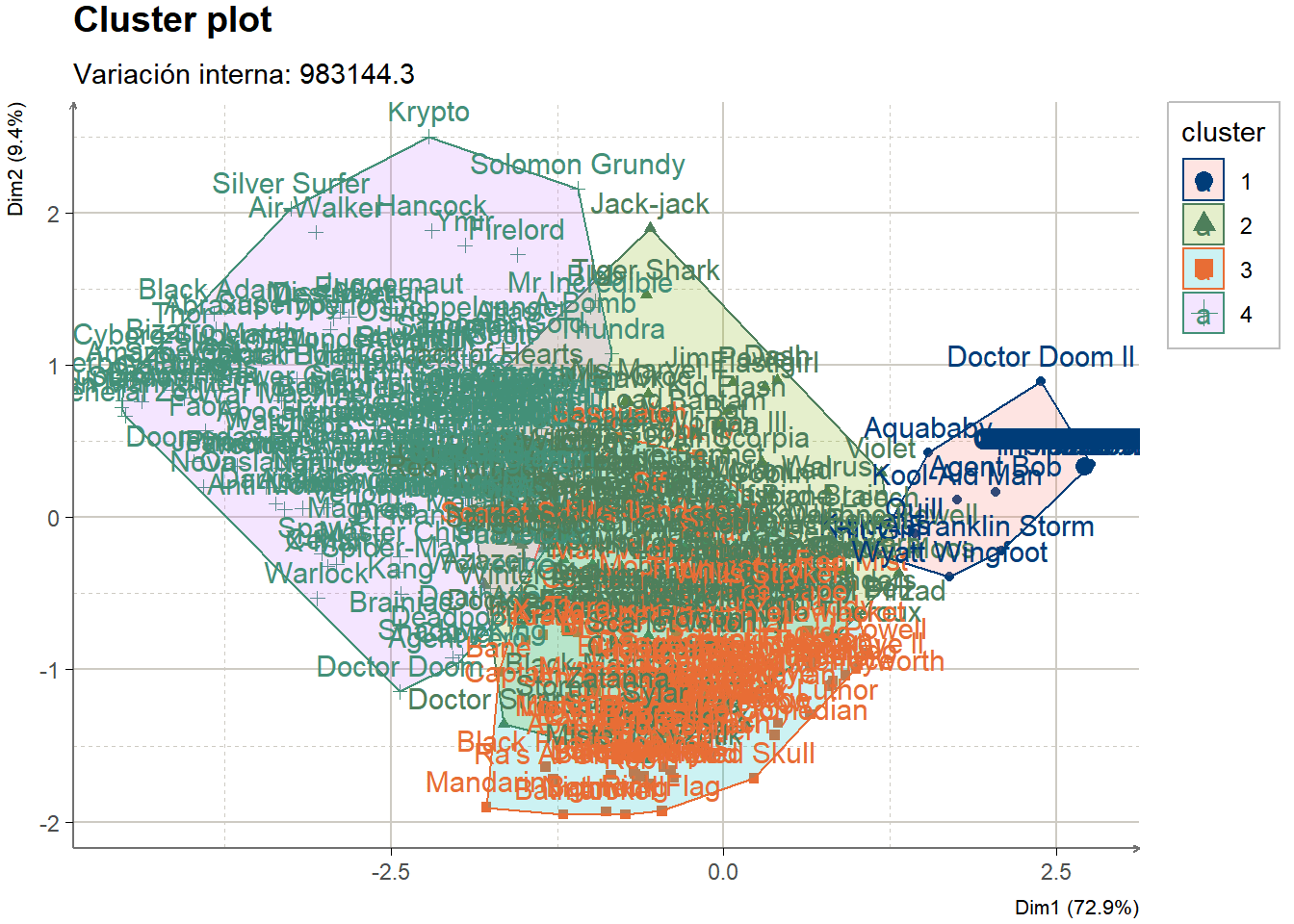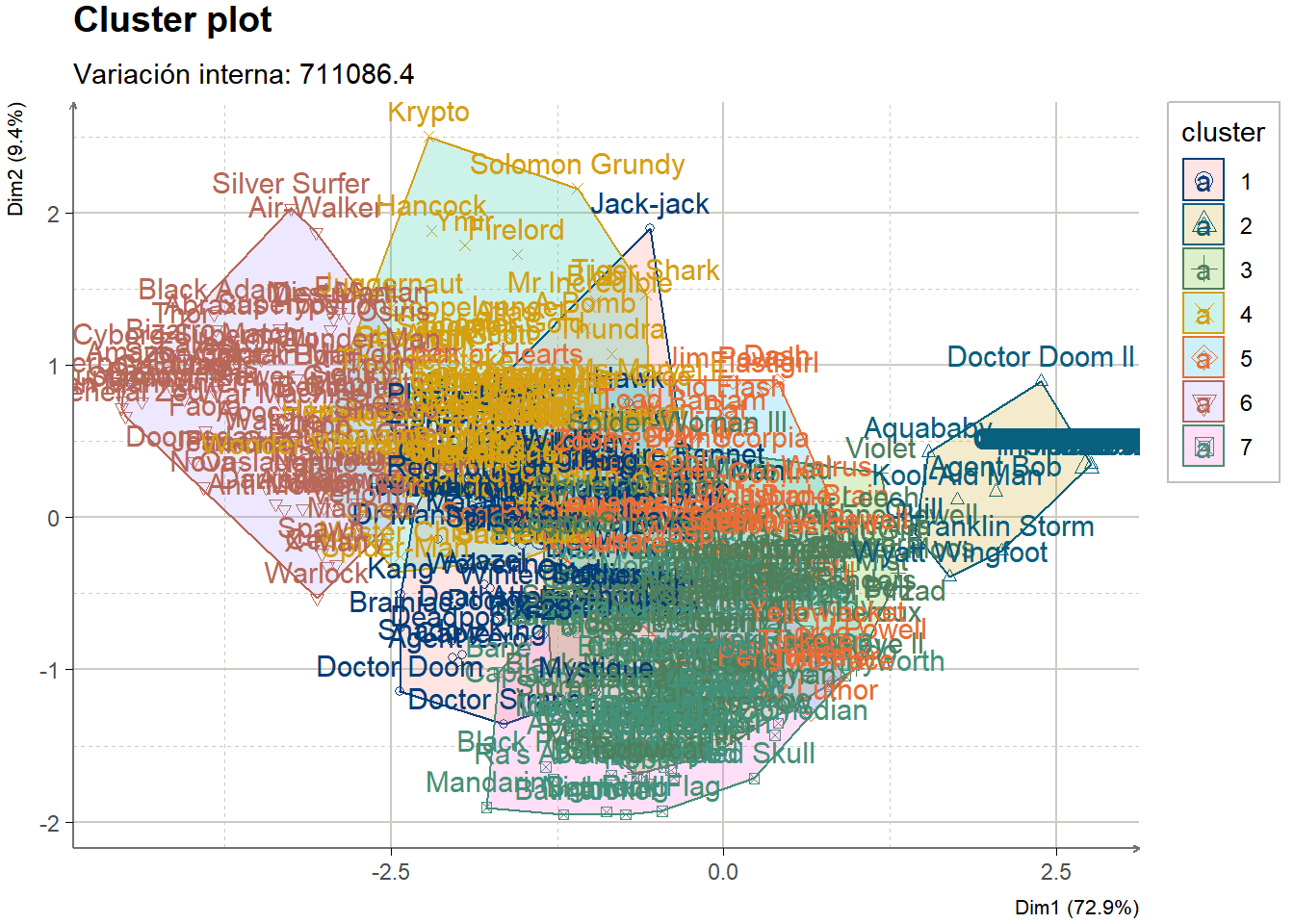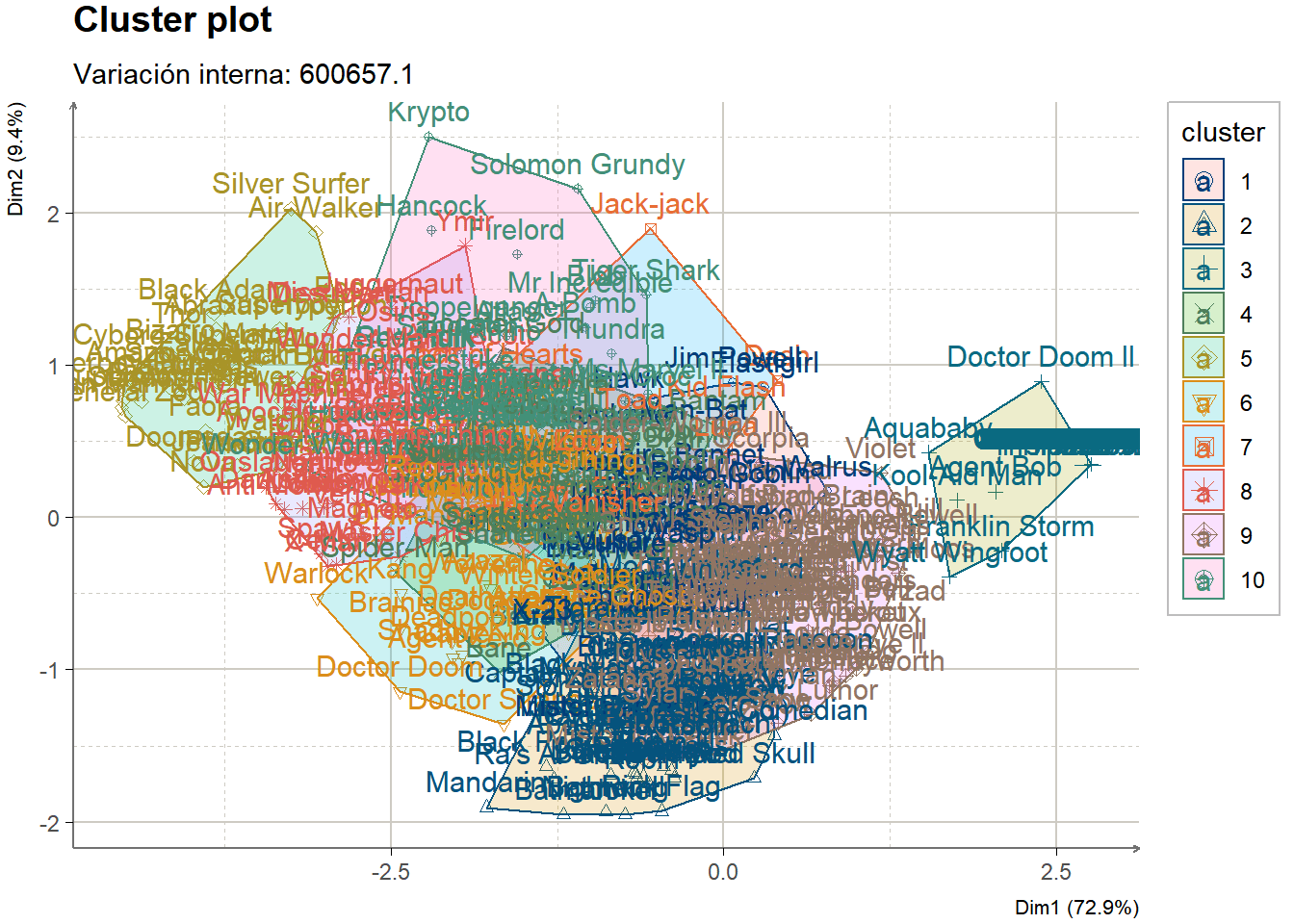
Ejercicios
Diseñe resultados que le permitan hacer evidentes las características de cada grupo.
¿Qué cantidad de grupos considera más adecuados?, ¿por qué?
Analize los resultados de los grupos con el resto de variables y comente.