Capítulo 14 Análisis factorial
14.1 Variables Latentes
En muchas ocasiones los datos multivariados son vistos como mediciones indirectas provenientes de una fuente subyacente que típicamente no puede ser medida directamente.
Por ejemplo:
Tests psicológicos y pedagógicos se usan como una forma de medir la inteligencia u otras habilidades mentales.
Los electroencefalogramas miden la actividad cerebral de forma indirecta usando señales electromagnéticas grabadas por sensores colocados en diferentes partes de la cabeza.
Los precios de las acciones en el mercado financiero reflejan factores no medidos como la confianza en el mercado o influencias externas que serían dificiles de medir o identificar.
El análisis factorial es una herramienta que permite identificar las fuentes latentes subyacentes a un conjunto de datos.
14.2 Solución factorial
La descomposición en valores singulares (13.1) tiene una representación en variables latentes.
Escribiendo \(S = \sqrt{N}U\), \(A^T = \frac{DV^T}{\sqrt{N}}\), tenemos \[X = SA^T\]
Y por tanto cada columna de \(X\) es una combinación lineal de las columnas de \(S\).
Dado que \(U\) es una matriz ortogonal y asumiendo que las columnas de \(X\) (y de \(U\)) tienen media cero tenemos que las columnas de \(S\) también tienen media cero, no están correlacionadas y tienen varianza unitaria.
En términos de variables aleatorias podemos interpretar a los componentes principales como una estimación del modelo de variables latentes:
\[X_1 = a_{11}S_1+a_{12}S_2+\dots +a_{1p}S_p\] \[X_2 = a_{21}S_1+a_{22}S_2+\dots +a_{2p}S_p\] \[\vdots\] \[X_p = a_{p1}S_1+a_{p2}S_2+\dots +a_{pp}S_p\]
o simplemente \(X = AS\).
Las variables \(X_j\), que están correlacionadas son representadas como una expasión lineal de las variables \(S_l\), no correlacionadas y de varianza unitaria.
Sin embargo, esto no es demasiado satisfactorio puesto que dada cualquier matriz ortogonal de \(p\times p\) en \(\mathbb{R}\) podemos escribir:
\[X = AS\] \[X = AR^TRS\] \[X = A^*S^*\]
Y \(Cov(S^*) = R Cov(S)R^T = I\)
Por lo tanto ha una infinidad de tales descomposiciones haciendo imposible identificar las variables latentes como fuentes subyacentes únicas.
El modelo clásico de factores resuelve este problema escribiendo el modelo como \(X = AS+\epsilon\). Donde \(A\) es la matriz de pesos de los factores, \(S\) un vector de \(q\) variables latentes y \(\epsilon_j\) son errores no correlacionados de media cero.
Comúnmente tanto \(S_j\) y \(\epsilon_j\) se modelan como variables aleatorias normales y el modelo factoria se ajusta por máxima verosimilitud.
Los parámetros dependen de la matriz de covarianzas
\[\Sigma = AA^T+D_{\epsilon}\]
Donde \(D_{\epsilon} = diag[Var(\epsilon_1),\dots , Var(\epsilon_p)]\).
Y dado que \(S_j\) son variables normales no correlacionadas entonces son variables aleatorias independientes.
La presencia de los errores \(\epsilon_j\) hace que el análisis de factores pueda verse como un modelo de la estructura de correlación de \(X_j\) en lugar de la estructura de covarianza (la usada en el análisis de componentes principales).
14.3 Rotaciones de factores
Como se menciona anteriormente las soluciones al modelo factorial podrían no ser únicas para encontrar la unicidad se introducen restricciones meramente arbitrarias.
Diferentes tipos de restricciones derivan en soluciones distintas al modelo.
Al proceso de cambiar de una solución a otra se le llama rotación y proviene de la representación geométrica del procedimiento.
La razón principal para rotar una solución es dar claridad a las cargas factoriales. Si la solución inicial es confusa una rotación puede proporcionar una estructura más fácil de interpretar.
14.3.1 Rotaciones ortogonales
Uno de los patrones de cargas factoriales más usuales y de hecho más deseables es la llamada estructura simple de pesos factoriales.
Se dice que los pesps factoriales presentan una estructura simple si cada variable tiene un gran peso en un solo factor, con pesos cercanos a cero en el resto de los factores.
Una de las rotaciones que procura generar una estructura de pesos simple son las rotaciones ortogonales (los nuevos ejes después de la rotación siguen siendo ortogonales).
14.3.2 Rotaciones oblicuas
Contrario a las rotaciones ortogonales, las rotaciones oblicuas permiten relajar la restricción de ortogonalidad con el fin de ganar simplicidad en la interpretación de los factores.
Con este método los factores resultan correlacionados, aunque generalmente esta correlación es pequeña.
El uso de rotaciones oblicuas se justifica porque en muchos contextos es lógico suponer que los factores están correlacionados.
14.4 Análisis factorial en R
Usando datos de gastos en hogares buscaremos identificar, a través de un análisis factorial, grupos de gastos generales.
## 'data.frame': 19479 obs. of 59 variables:
## $ folioviv : num 1e+08 1e+08 1e+08 1e+08 1e+08 ...
## $ foliohog : int 1 1 1 1 1 1 1 1 1 1 ...
## $ ubica_geo : int 10010001 10010001 10010001 10010001 10010001 10010001 10010001 10010001 10010001 10010001 ...
## $ tam_loc : int 1 1 1 1 1 1 1 1 1 1 ...
## $ est_socio : int 4 4 4 4 4 4 4 4 4 3 ...
## $ clase_hog : int 3 1 2 3 2 3 2 2 2 3 ...
## $ sexo_jefe : int 2 1 1 1 1 1 1 1 1 1 ...
## $ edad_jefe : int 77 64 60 79 72 67 58 50 56 44 ...
## $ educa_jefe: int 8 6 8 10 10 10 8 11 6 9 ...
## $ tot_integ : int 2 1 3 3 3 4 3 4 4 7 ...
## $ hombres : int 1 1 1 3 2 1 2 3 1 4 ...
## $ mujeres : int 1 0 2 0 1 3 1 1 3 3 ...
## $ mayores : int 2 1 3 3 3 4 3 4 4 6 ...
## $ menores : int 0 0 0 0 0 0 0 0 0 1 ...
## $ p12_64 : int 0 1 3 2 1 2 3 4 4 5 ...
## $ p65mas : int 2 0 0 1 2 2 0 0 0 1 ...
## $ ocupados : int 0 0 2 2 1 1 2 1 4 4 ...
## $ ing_cor : num 39787 19524 101214 87884 86261 ...
## $ cereales : num 681 231 591 1646 1491 ...
## $ carnes : num 51.4 0 3529.3 64.3 4382.9 ...
## $ pescado : num 0 0 0 0 0 0 0 0 0 0 ...
## $ leche : num 759 424 1286 1144 759 ...
## $ huevo : num 141 0 347 283 386 ...
## $ aceites : num 0 0 0 0 0 0 0 0 0 0 ...
## $ tuberculo : num 0 0 103 0 129 ...
## $ verduras : num 283 0 707 810 746 ...
## $ frutas : num 1620 579 476 1260 698 ...
## $ azucar : num 0 0 0 0 0 0 0 0 0 0 ...
## $ cafe : num 0 0 0 0 0 0 0 0 0 0 ...
## $ especias : num 0 0 0 0 0 ...
## $ otros_alim: num 7637 0 5413 3471 2571 ...
## $ bebidas : num 0 0 2301 0 1067 ...
## $ ali_fuera : num 0 707 2006 0 643 ...
## $ tabaco : num 0 0 0 0 0 ...
## $ vestido : num 0 0 489 293 0 ...
## $ calzado : num 401 0 0 0 0 ...
## $ alquiler : num 0 0 0 0 0 ...
## $ pred_cons : num 505 0 138 125 212 ...
## $ agua : num 294 0 600 300 900 ...
## $ energia : num 1400 0 2252 675 1950 ...
## $ limpieza : num 1003 212 1866 2879 0 ...
## $ cuidados : num 514 212 1632 2860 0 ...
## $ utensilios: num 0 0 234.8 19.6 0 ...
## $ enseres : num 489 0 0 0 0 ...
## $ atenc_ambu: num 1370 0 1125 421 0 ...
## $ hospital : num 0 0 0 0 0 0 0 0 0 0 ...
## $ medicinas : num 32.3 117.4 117.4 0 0 ...
## $ publico : num 0 0 386 0 0 ...
## $ foraneo : num 0 0 0 0 0 ...
## $ adqui_vehi: num 0 0 0 0 0 0 0 0 0 0 ...
## $ mantenim : num 4381 0 2903 0 5806 ...
## $ refaccion : num 1957 0 0 0 0 ...
## $ combus : num 2424 0 2903 0 5806 ...
## $ comunica : num 1110 0 2540 1440 1200 ...
## $ educacion : num 0 0 0 3019 0 ...
## $ esparci : num 900 0 0 0 1050 ...
## $ paq_turist: num 0 0 0 0 0 0 0 0 0 0 ...
## $ cuida_pers: num 438.4 203.2 1622.9 847.7 95.8 ...
## $ acces_pers: num 0 0 0 0 0 ...Trabajaremos solamente con la información relacionada a gastos.
## In smc, smcs < 0 were set to .0
## In smc, smcs < 0 were set to .0
## In smc, smcs < 0 were set to .0## In factor.scores, the correlation matrix is singular, an approximation is used## Scale for 'y' is already present. Adding another scale for 'y', which
## will replace the existing scale.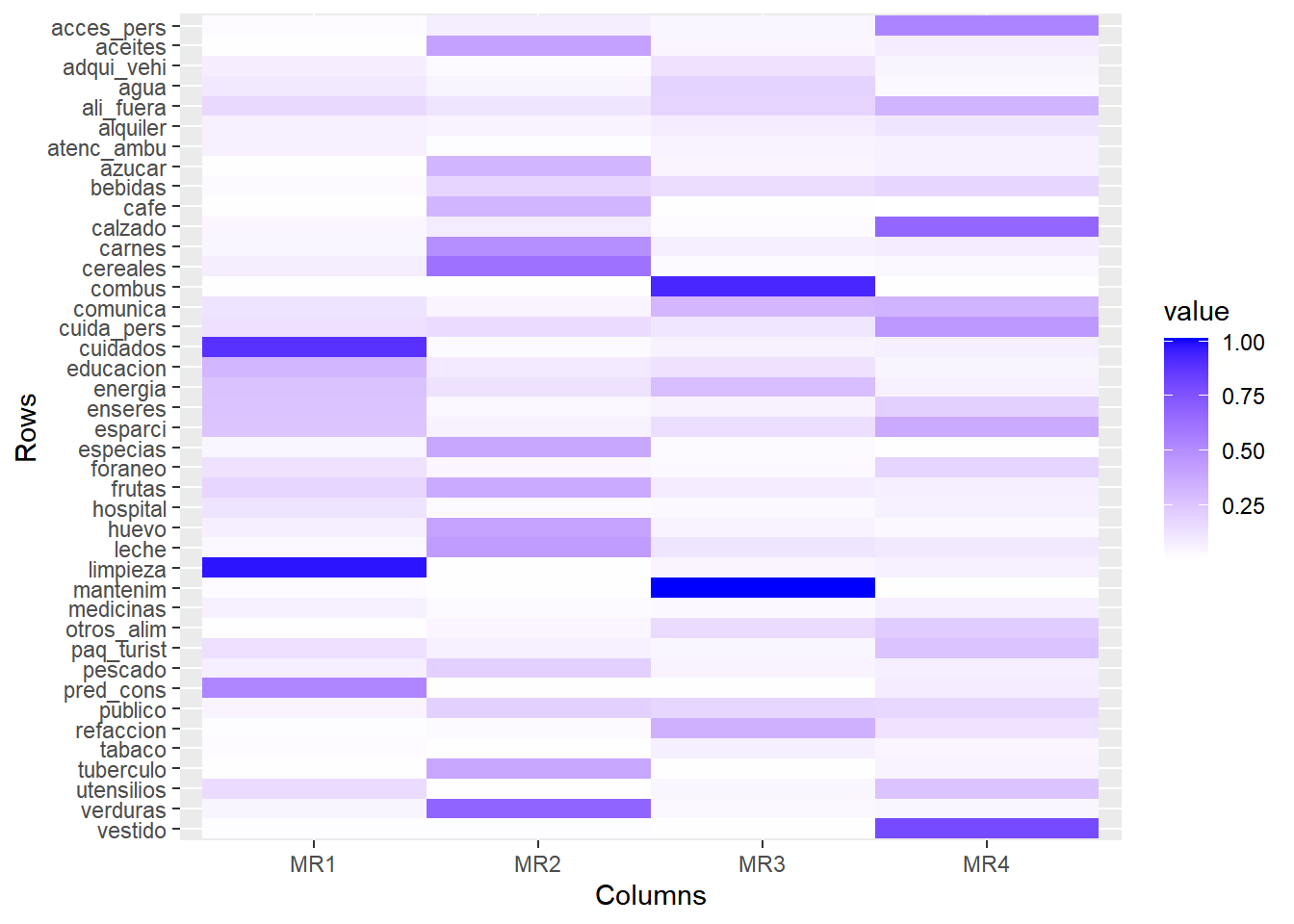
Ejercicios:
¿Considera que los factores son buenos?
¿Qué problema encuentra en los datos que puedan causar una mala optimización en la búsqueda de los factores?
Analize detalladamente los datos y proponga alguna solución si es que considera que hay problemas en los datos.
Vuelva aplicar el análisis factorial.
¿Cómo interpretaría los factores?