Capítulo 9 Antecedentes
También llamados métodos basados en árboles, son algorítmos que hacen particiones al espacio de covariables y a cada una de ellas le ajustan un modelo simple, por ejemplo una constante.
Para hacer la tarea sencilla pensemos las particiones como binarias, es decir, el primer pasó será partir el espacio de covariables en dos, luego cada parte se divide en dos regiones más y continuamos el proceso hasta cumplir alguna regla de paro.
Una parte muy importante de este tipo de modelos binarios es la interpretabilidad pues el árbol estratifica la población de acuerdo a sus características.
9.1 Árboles de regresión
Supongamos que tenemos \(p\) covariables, una variable de respuesta/objetivo y \(N\) observaciones. El argoritmo debe poder decidir las variables a particionar, los puntos de quiebre y la topología del árbol.
Supongamos que tenemos una partición de en \(M\) regiones \(R_1,R_2,\dots,R_M\) y modelamos la respuesta como la constante \(c_m\) en cada región:
\[f(x)=\sum_{m=1}^M c_mI(x\in R_m)\]
Si tomamos como criterio minimizar la suma de cuadrados \(\sum(y_i-f(x_i))^2\), es sencillo obtener que la mejor \(\hat{c}_m\) es el promedio de \(y_i\) en la región \(R_m\):
\[\hat{c}_m=prom(y_i|x_i\in R_m)\]
Ahora para encontrar la mejor partición binaria en términos de la suma de cuadrados seguimos lo siguiente pasos:
Consideremos la variable de partición \(j\) y el punto de quiebre \(s\) definimos el par de semiplanos
\[R_1(j,s)=\{X|X_j\leq s\}\]
\[R_2(j,s)=\{X|X_j >s\}\]
Entonces buscamos la variabe \(j\) y el punto de quiebre \(s\) que resuelve
\[\min_{j,s}[\min_{c_1}\sum_{x_i\in R_1(j,s)}(y_i-c_1)^2+\min_{c_2}\sum_{x_i\in R_2(j,s)}(y_i-c_2)^2]\]
Para cualquier elección de \(j\) y \(s\) la minimización dentro de los corchetes se resuelve como
\[\hat{c}_1=prom(y_i|x_i \in R_1(j,s))\] y \[\hat{c}_2=prom(y_i|x_i \in R_2(j,s))\]
Para cada variable de partición, encontrar el punto de quiebre \(s\) se puede hacer muy rápidamente pasando por todos los puntos.
Una vez encontrada la mejor partición, volvemos a hacer particiones siguiendo el mismo método.
¿Qué tanto debemos dejar que un árbol crezca?
El crecimiento de un árbol hace referencia a la cantidad de particiones que contiene. En este sentido un árbol muy grande podría sobre ajustar los datos mientras que uno muy pequeño podría no capturar la estructura de ellos.
El tamaño del árbol es un parámetro que incide directamente en la complejidad del modelo y el tamaño óptimo debe ser elegido de forma adaptativa según los datos.
La solución usada es dejar crecer el árbol (\(T_0\)) hasta tener un tamaño de nodo específico y entonces podar el árbol usando una estrategia costo-complejidad como mostramos en seguida.
Definimos un sub-árbol \(T \subset T_0\) como cualquier árbol que pueda ser obtenido de podar el árbol \(T_0\), es decir, colapsar el número de sus nodos internos.
Indexemos los nodos terminales con \(m\), siendo el nodo \(m\) representante de la región \(R_m\). Sea \(|T|\) el número de nodos terminales en el árbol \(T\) y sean
\[N_m=\#\{x_i\in R_m\}\]
\[\hat{c}_m=\frac{1}{N_m}\sum_{x_i\in R_m}y_i\]
\[Q_m(T)=\frac{1}{N_m}\sum_{x_i\in R_m}(y_i-\hat{c}_m)^2\]
definimos entonces el criterio costo-complejidad como:
\[C_\alpha(T)=\sum_{m=1}^{|T|}N_mQ_m(T)+\alpha |T|\]
La idea es encontrar, para cada \(\alpha\), el sub-árbol \(T_\alpha \subseteq T_0\) que minimice \(C_\alpha(T)\).
El parámetro \(\alpha \geq 0\) controla el tradeoff entre el tamaño del árbol y la bondad de ajuste a los datos. Valores grandes de \(\alpha\) resultará en árboles pequeños y viceversa.
9.2 Árboles de clasificación
Si el objetivo es clasificar los cambios necesarios al algoritmo ocurren en los criterios de partición y de poda. Para árboles de regresión usamos la medida de impureza del nodo, error cuadrático, \(Q_m(T)\) pero ésta no es útil para clasificación.
Para cada nodo \(m\), representando una región \(R_m\) con \(N_m\) observaciones sea
\[\hat{p}_{mk}=\frac{1}{N_m}\sum_{x_i\in R_m}I(y_i=k)\]
la proporción de observaciones de la clase \(k\) en el nodo \(m\).
Clasificamos, entonces, las observaciones en el nodo \(m\) a la clase \(k(m)=\arg \max_k \ \hat{p}_{mk}\), es decir, la clase mayoritaria en el nodo \(m\). Algunas medidas \(Q_m(T)\) de impureza del nodo son:
Error de clasificación: \(\frac{1}{N_m}\sum_{i \in R_m}I(y_i \neq k(m))=1-\hat{p}_{mk(m)}\)
Índice GINI: \(\sum_{k \ne k'}\hat{p}_{mk}\hat{p}_{mk'}=\sum_{k=1}^K\hat{p}_{mk}(1-\hat{p}_{mk})\)
Entropía cruzada: \(-\sum_{k=1}^K\hat{p}_{mk}\log\hat{p}_{mk}\)
En el caso de dos clases, si \(p\) es la proporción de la segunda clase, las medidas son:
Error de clasificación: \(1-max(p,1-p)\)
Índice GINI: \(2p(1-p)\)
Entropía: \(-p\log p-(1-p) \log (1-p)\)
9.3 Algunos problemas en los árboles
9.3.1 Covariables categóricas
Al trabajar con una covariable/predictora categórica con \(q\) posibles valores existen \(2^{q-1}-1\) posibles particiones binarias y el tiempo de computación se vuelve enorme para valores grandes de \(q\).
Sin embargo si tenemos un problema de clasificación de dos clases \((0,1)\) podemos simplificar el problema ordenando los valores de la variable categórica de acuerdo a la propoción en la clase 1, entonces hacemos las particiones como si la variable fuera ordinal.
Es posible demostrar que este procedimiento logra la partición óptima en términos de entropía o índice Gini de entre las \(2^{q-1}-1\) posibles.
9.3.2 La matriz de pérdida
En problemas de clasificación, las consecuencias de hacerlo incorrectamente pueden ser más importantes para alguna clase que para otras.
Para resolver esta situación definimos una matriz de pérdida \(L\) de \(K\times K\), con \(L_{kk'}\) siendo la pérdida incurrida por clasificar erroneamente una clase \(k\) como una \(k'\). Típicamente \(L_{kk}=0\ \forall k\).
Para incorporar las pérdidas en el modelo podemos modificar el índice Gini como \(\sum_{k \neq k'}L_{kk'}\hat{p}_{mk}\hat{p}_{mk'}\).
Aunque en el caso de \(k>2\) clases es muy útil, no lo es para el caso \(k=2\), ¿por qué?
9.4 Árboles en R
En este ejemplo crearemos un árbol de clasificación que nos ayude a identificar a personajes de marvel como buenos o malos.
Los datos que usaremos son estadísticas de cada personaje:
| name | alignment | intelligence | strength | speed | durability | power | combat | total |
|---|---|---|---|---|---|---|---|---|
| 3-D Man | good | 50 | 31 | 43 | 32 | 25 | 52 | 233 |
| A-Bomb | good | 38 | 100 | 17 | 80 | 17 | 64 | 316 |
| Abe Sapien | good | 88 | 14 | 35 | 42 | 35 | 85 | 299 |
| Abin Sur | good | 50 | 90 | 53 | 64 | 84 | 65 | 406 |
| Abomination | bad | 63 | 80 | 53 | 90 | 55 | 95 | 436 |
| Abraxas | bad | 88 | 100 | 83 | 99 | 100 | 56 | 526 |
| Adam Monroe | good | 63 | 10 | 12 | 100 | 71 | 64 | 320 |
| Adam Strange | good | 1 | 1 | 1 | 1 | 0 | 1 | 5 |
| Agent 13 | good | 1 | 1 | 1 | 1 | 0 | 1 | 5 |
| Agent Bob | good | 10 | 8 | 13 | 5 | 5 | 20 | 61 |
Eliminaremos las variables Name y Total para construir el árbol. Usaremos las librerías rpart y rpart.plot para construir el modelo y la visualización.
Construimos el árbol:
## n= 597
##
## node), split, n, loss, yval, (yprob)
## * denotes terminal node
##
## 1) root 597 165 good (0.2763819 0.7236181)
## 2) intelligence>=84.5 76 38 bad (0.5000000 0.5000000)
## 4) power< 29 10 2 bad (0.8000000 0.2000000) *
## 5) power>=29 66 30 good (0.4545455 0.5454545)
## 10) power>=46.5 54 24 bad (0.5555556 0.4444444)
## 20) intelligence< 97 35 12 bad (0.6571429 0.3428571)
## 40) strength>=56 26 5 bad (0.8076923 0.1923077) *
## 41) strength< 56 9 2 good (0.2222222 0.7777778) *
## 21) intelligence>=97 19 7 good (0.3684211 0.6315789) *
## 11) power< 46.5 12 0 good (0.0000000 1.0000000) *
## 3) intelligence< 84.5 521 127 good (0.2437620 0.7562380)
## 6) intelligence>=72 76 26 good (0.3421053 0.6578947)
## 12) speed< 16.5 8 2 bad (0.7500000 0.2500000) *
## 13) speed>=16.5 68 20 good (0.2941176 0.7058824) *
## 7) intelligence< 72 445 101 good (0.2269663 0.7730337) *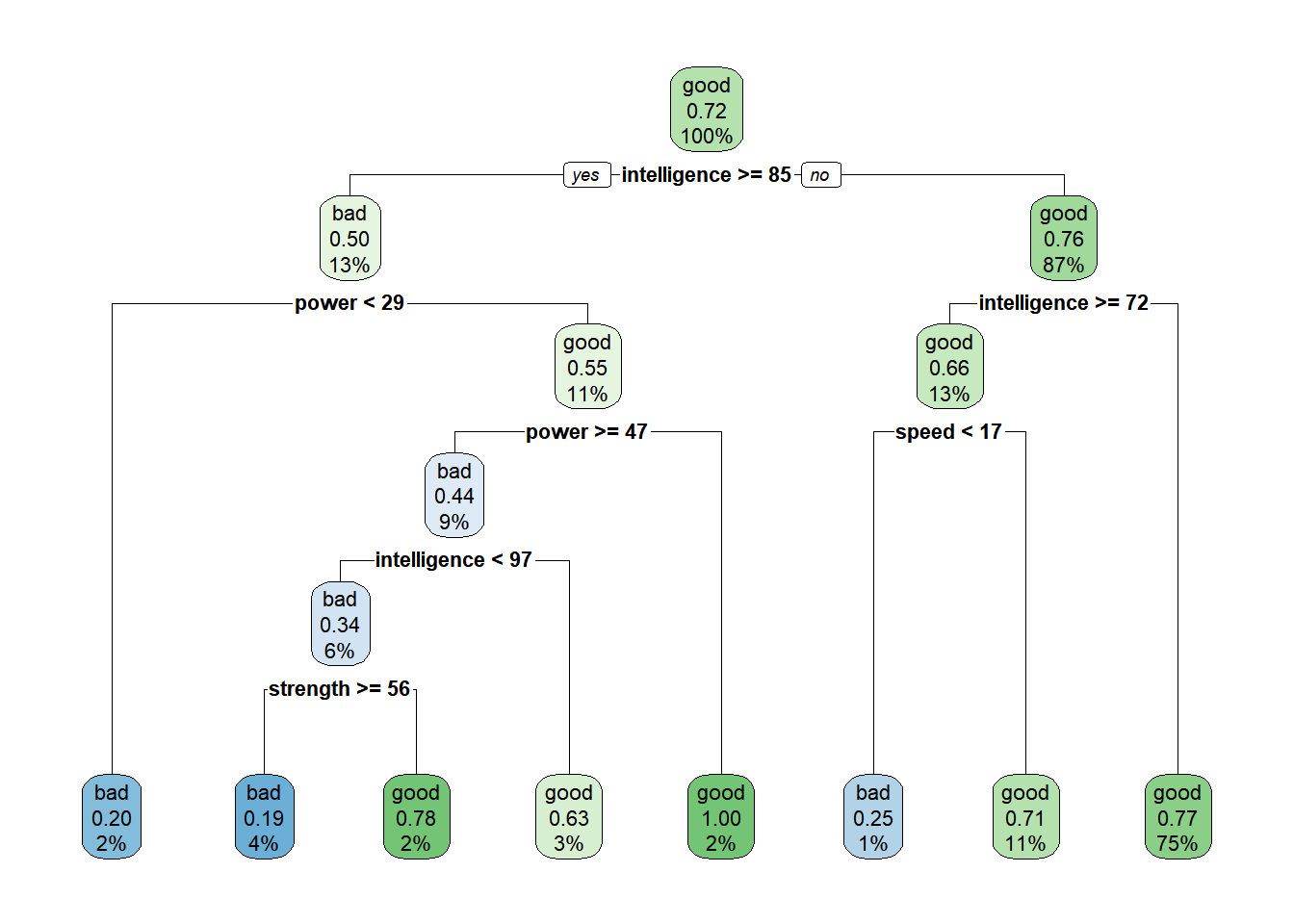
Métricas de ajuste:
## Confusion Matrix and Statistics
##
## Reference
## Prediction bad good
## bad 35 130
## good 9 423
##
## Accuracy : 0.7672
## 95% CI : (0.7312, 0.8005)
## No Information Rate : 0.9263
## P-Value [Acc > NIR] : 1
##
## Kappa : 0.2473
##
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.7649
## Specificity : 0.7955
## Pos Pred Value : 0.9792
## Neg Pred Value : 0.2121
## Prevalence : 0.9263
## Detection Rate : 0.7085
## Detection Prevalence : 0.7236
## Balanced Accuracy : 0.7802
##
## 'Positive' Class : good
## 9.4.1 Ejercicios
¿Cómo interpretaría el modelo?
¿Considera que el modelo es bueno?
Modifique el modelo para lograr un mejor accuracy de predicción.
Explore los parámetros de la función
rpart.ploty diseñe una función que ajuste el modelo y lo grafique con el diseño que para usted sea el más informativo.Explique el modelo detalladamente.